MPI
The Message Passing Interface is a communication protocol for programming parallel computers. Both point-to-point and collective communication are supported. Tolosa heavily relies on MPI to build its parallel environment. Several structures were created to make the communications' implementation easier.
Collective communications
Fortran structure
The mpi_pool structure defines a pool of MPI processes and basic operations on those processes. This structure enables collective communications inside a communicator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | TYPE mpi_pool
integer(ip) :: comm ! Communicators Pool (mpi_comm_world for whole)
integer(ip) :: size ! Number of ranks in Pool
integer(ip) :: rank ! Rank Number from 0 to size-1
integer(ip) :: err ! Usefull to test an error at output of an MPI routine
integer(ip), allocatable :: rankorder(:)
logical :: is_init = .false.
CONTAINS
procedure, pass( self ) :: init => mpi_init_
procedure, pass( self ) :: final => mpi_final_
procedure, pass( self ) :: waitall => mpi_wait_all
procedure, pass( self ) :: barrier => mpi_wait_all
procedure, pass( self ) :: sum => mpi_sum_
procedure, pass( self ) :: prod => mpi_prod_
procedure, pass( self ) :: min => mpi_min_
procedure, pass( self ) :: max => mpi_max_
procedure, pass( self ) :: bcast => mpi_bcast_
procedure, pass( self ) :: mpi_allgather_i , mpi_allgather_r
generic :: allgather => mpi_allgather_i , mpi_allgather_r
END TYPE mpi_pool
|
To initialize a pool of MPI processes, one has to call the mpi_init_ subroutine.
| MODULE SUBROUTINE mpi_init_( self )
class(mpi_pool), intent(inout) :: self
END SUBROUTINE mpi_init_
|
All the collective communications and collective operations are facilitated. The MPI operations enabling data communications (MPI_BCAST(), MPI_SCATTER(), MPI_GATHER(), MPI_ALLGATHER(), MPI_ALLTOALL()), data operations and communications (MPI_REDUCE(), MPI_ALLREDUCE()), and global synchronization (MPI_BARRIER()) are easily implemented in the following subroutines :
Collective operations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59 | MODULE SUBROUTINE mpi_wait_all( self )
class(mpi_pool), intent(inout) :: self
END SUBROUTINE mpi_wait_all
MODULE SUBROUTINE mpi_sum_( self , val )
class(mpi_pool), intent(inout) :: self
class(*) , intent(inout) :: val
END SUBROUTINE mpi_sum_
MODULE SUBROUTINE mpi_prod_( self , val )
class(mpi_pool), intent(inout) :: self
class(*) , intent(inout) :: val
END SUBROUTINE mpi_prod_
MODULE SUBROUTINE mpi_max_( self , val , which )
class(mpi_pool), intent(inout) :: self
class(*) , intent(inout) :: val
integer(ip) , intent( out), optional :: which
END SUBROUTINE mpi_max_
MODULE SUBROUTINE mpi_min_( self , val , which )
class(mpi_pool), intent(inout) :: self
class(*) , intent(inout) :: val
integer(ip) , intent( out), optional :: which
END SUBROUTINE mpi_min_
MODULE SUBROUTINE mpi_bcast_( self , val , proc )
class(mpi_pool), intent(inout) :: self
class(*) , intent(inout) :: val
integer(ip) , intent(in ) :: proc
END SUBROUTINE mpi_bcast_
MODULE SUBROUTINE mpi_allgather_i( self , val , allgather )
class(mpi_pool), intent(inout) :: self
integer(ip) , intent(in ) :: val
integer(ip) , intent(inout) :: allgather( np )
END SUBROUTINE mpi_allgather_i
MODULE SUBROUTINE mpi_allgather_r( self , val , allgather )
class(mpi_pool), intent(inout) :: self
real(rp) , intent(in ) :: val
real(rp) , intent(inout) :: allgather( np )
END SUBROUTINE mpi_allgather_r
|
When the pool of MPI processes is no longer needed, one has to finalize MPI by calling the mpi_final_ subroutine.
| MODULE SUBROUTINE mpi_final_( self )
class(mpi_pool), intent(inout) :: self
END SUBROUTINE mpi_final_
|
Usage
To be able to use this structure, one has to initialize a the MPI environment with a new mpi_pool object first.
type(mpi_pool) :: mpi_world
[...]
call mpi_world%init
When the MPI pool is initialized, one can call specific operations. For example, one can gather all the processes' rank in one table by writting :
integer :: rank
integer, allocatable :: gath_rank(:)
type(mpi_pool) :: mpi_world
[...]
rank = mpi_world%rank
allocate( gath_rank( mpi_world%size ) )
call mpi_world%allgather( rank , gath_rank )
[...]
When the collective communications and operations are no longer needed, one can finalize MPI :
type(mpi_pool) :: mpi_world
[...]
call mpi_world%final
Point-to-point communications
Fortran structure
The mpi_mess structure represents a process with its rank, and other parameters used for the point-to-point communication. The mpi_com structure defines a point-to-point communication between two processes s and r. The mpi_com%pool points to a pool of MPI processes, previously defined as mpi_world ; this will enable one to identify the current process in the pool.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76 | TYPE mpi_mess
integer(ip) :: rank = 0_ip
integer(ip) :: count = 1_ip
integer(ip) :: istart = 1_ip
integer(ip) :: tag = 0_ip
integer(ip) :: typ_i
integer(ip) :: typ_r
integer :: req
integer(ip) :: err
integer(ip), allocatable :: d(:)
integer(ip), allocatable :: l(:)
integer(ip) :: n
integer(ip) :: typ
END TYPE mpi_mess
TYPE mpi_com
type(mpi_pool), pointer :: pool => mpi_world
type(mpi_mess) :: s
type(mpi_mess) :: r
integer(ip) :: err
logical :: twoside = .false.
logical :: is_init = .false.
CONTAINS
procedure :: equal_mpi_com
procedure, pass( self ) :: reset => reset_mpi_com
procedure, pass( self ) :: init => initialize_mpi_com
procedure, pass( self ) :: replace => replace_mpi_com
procedure, pass( self ) :: wait_send => mpi_com_wait_send
procedure, pass( self ) :: wait_recv => mpi_com_wait_recv
procedure, pass( self ) :: wait => mpi_com_wait
procedure, pass( self ) :: regen_typ_to_send => mpi_com_regen_typ_to_send
procedure, pass( self ) :: regen_typ_to_recv => mpi_com_regen_typ_to_recv
procedure, pass( self ) :: regen_typ => mpi_com_regen_typ
procedure, pass( self ) :: mpi_com_send_scalar_i , &
mpi_com_send_scalar_r , &
mpi_com_recv_scalar_i , &
mpi_com_recv_scalar_r , &
mpi_com_send_array_i , &
mpi_com_recv_array_i , &
mpi_com_send_array_r , &
mpi_com_recv_array_r , &
mpi_com_send_recv_scalar_i , &
mpi_com_send_recv_scalar_r , &
mpi_com_send_recv_array_i , &
mpi_com_send_recv_array_r , &
mpi_com_gen_typ_to_send_indexed , &
mpi_com_gen_typ_to_recv_indexed , &
mpi_com_gen_typ_to_send_contiguous , &
mpi_com_gen_typ_to_recv_contiguous
generic :: assignment(=) => equal_mpi_com
generic :: send => mpi_com_send_scalar_i , &
mpi_com_send_scalar_r , &
mpi_com_send_array_i , &
mpi_com_send_array_r
generic :: recv => mpi_com_recv_scalar_i , &
mpi_com_recv_scalar_r , &
mpi_com_recv_array_i , &
mpi_com_recv_array_r
generic :: send_recv => mpi_com_send_recv_scalar_i , &
mpi_com_send_recv_scalar_r , &
mpi_com_send_recv_array_i , &
mpi_com_send_recv_array_r
generic :: gen_typ_to_send => mpi_com_gen_typ_to_send_indexed , &
mpi_com_gen_typ_to_send_contiguous
generic :: gen_typ_to_recv => mpi_com_gen_typ_to_recv_indexed , &
mpi_com_gen_typ_to_recv_contiguous
END TYPE mpi_com
|
When initializing the point-to-point communicator by calling the initialize_mpi_com subroutine, one has to define the ranks of the processes sending and receiving the data. If the data to be communicated is an array, and one wishes to send and receive only a portion of the array, one can enter the send_istart, recv_istart, send_count, recv_count values. If both processes need to send and receive data, one has to define twoside = .true. . A pool of MPI processes will also be defined ; if the pool is not specified at the initialization, a pool of all MPI processes will be defined.
Info
At each point-to-point communication initialization, the previous parameters of the mpi_com object will be reset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44 | MODULE SUBROUTINE initialize_mpi_com( self , send_rank , recv_rank , &
send_istart , recv_istart , &
send_count , recv_count , twoside , pool )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(in ) :: send_rank
integer(ip) , intent(in ) :: recv_rank
integer(ip) , intent(in ), optional :: send_istart
integer(ip) , intent(in ), optional :: recv_istart
integer(ip) , intent(in ), optional :: send_count
integer(ip) , intent(in ), optional :: recv_count
logical , intent(in ), optional :: twoside
type(mpi_pool), intent(in ), optional, target :: pool
END SUBROUTINE initialize_mpi_com
MODULE SUBROUTINE reset_mpi_com( self )
class(mpi_com), intent(inout) :: self
END SUBROUTINE reset_mpi_com
MODULE SUBROUTINE equal_mpi_com( this , from )
class(mpi_com), intent(inout) :: this
type(mpi_com) , intent(in ) :: from
END SUBROUTINE equal_mpi_com
MODULE SUBROUTINE replace_mpi_com( self , send_rank , recv_rank , &
send_istart , recv_istart , &
send_count , recv_count , twoside , pool )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(in ), optional :: send_rank
integer(ip) , intent(in ), optional :: recv_rank
integer(ip) , intent(in ), optional :: send_istart
integer(ip) , intent(in ), optional :: recv_istart
integer(ip) , intent(in ), optional :: send_count
integer(ip) , intent(in ), optional :: recv_count
logical , intent(in ), optional :: twoside
type(mpi_pool), intent(in ), optional, target :: pool
END SUBROUTINE replace_mpi_com
|
When the communication is initialized, all point-to-point communications are facilitated. One can run blocking and non blocking communications. Non blocking communications are send and recv. Blocking communications are enabled by calling send_recv. One can also wait for the end of a non blocking communication by calling wait, wait_send, wait_recv.
Wait for the end of a non blocking communication
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | MODULE SUBROUTINE mpi_com_wait_send( self )
class(mpi_com), intent(inout) :: self
END SUBROUTINE mpi_com_wait_send
MODULE SUBROUTINE mpi_com_wait_recv( self )
class(mpi_com), intent(inout) :: self
END SUBROUTINE mpi_com_wait_recv
MODULE SUBROUTINE mpi_com_wait( self )
class(mpi_com), intent(inout) :: self
END SUBROUTINE mpi_com_wait
|
Non blocking communications
The following subroutines define the exchange of an integer. The subroutines defining the exchange of a real are equivalent.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | MODULE SUBROUTINE mpi_com_send_scalar_i( self , to_send , send_rank , withinfo )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(in ) :: to_send
integer(ip) , intent(in ), optional :: send_rank
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_com_send_scalar_i
MODULE SUBROUTINE mpi_com_recv_scalar_i( self , to_recv , recv_rank , withinfo )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(inout) :: to_recv
integer(ip) , intent(in ), optional :: recv_rank
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_com_recv_scalar_i
MODULE SUBROUTINE mpi_com_send_array_i( self , to_send , send_rank , withinfo )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(in ) :: to_send(:)
integer(ip) , intent(in ), optional :: send_rank
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_com_send_array_i
MODULE SUBROUTINE mpi_com_recv_array_i( self , to_recv , recv_rank , withinfo )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(inout) :: to_recv(:)
integer(ip) , intent(in ), optional :: recv_rank
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_com_recv_array_i
|
Blocking communications
The following subroutines define the exchange of an integer. The subroutines defining the exchange of a real are equivalent.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | MODULE SUBROUTINE mpi_com_send_recv_scalar_i( self , to_send , send_rank , &
to_recv , recv_rank , withinfo )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(inout) :: to_send
integer(ip) , intent(inout), optional :: to_recv
integer(ip) , intent(in ), optional :: send_rank
integer(ip) , intent(in ), optional :: recv_rank
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_com_send_recv_scalar_i
MODULE SUBROUTINE mpi_com_send_recv_array_i( self , to_send , send_rank , &
to_recv , recv_rank , withinfo , withtmp )
class(mpi_com), intent(inout) :: self
integer(ip) , intent(inout) :: to_send(:)
integer(ip) , intent(inout), optional :: to_recv(:)
integer(ip) , intent(in ), optional :: send_rank
integer(ip) , intent(in ), optional :: recv_rank
logical , intent(in ), optional :: withinfo
logical , intent(in ), optional :: withtmp
END SUBROUTINE mpi_com_send_recv_array_i
|
Question
gen_typ_to_send ???
Usage
To initialize a point-to-point communication between two processes ranked 0 and 1, one can write :
type(mpi_com) :: mpi
call mpi%init( send_rank = 0 , recv_rank = 1 )
One can choose to have a non-blocking communication to send an array by simply writting :
type(mpi_com) :: mpi
real, allocatable :: to_send(:)
real, allocatable :: to_recv(:)
[...]
call mpi%send( to_send(:) )
call mpi%recv( to_recv(:) )
[...]
Wait for a non-blocking communication
To wait for a non-blocking communication to be over, one can add :
at the end of a communication.
One can also have a blocking communication. Here, the process 0 is sending a scalar to the process 1 :
type(mpi_com) :: mpi
integer :: a
[...]
call mpi%send_recv( to_send = a )
Info
One can also specify the name of the receiving variable by adding to_recv = 'name' in the mpi%send_recv call.
If both processes are sending and receiving data to and from the other process, one should specify that the communication is on both sides, and send and receive data by writting :
type(mpi_com) :: mpi
integer :: a_send, a_recv
[...]
call mpi%replace( twoside = .true. )
call mpi%send_recv( to_send = a_send , &
to_recv = a_recv )
Change the communicating processes
If another communication between other processes is needed, one can change the communicating processes without calling the replace subroutine simply by specifying send_rank and recv_rank in the call of the new communication.
Graph communications
Fortran structure
The mpi_grph structure defines point-to-point communications in a graph of MPI processes.
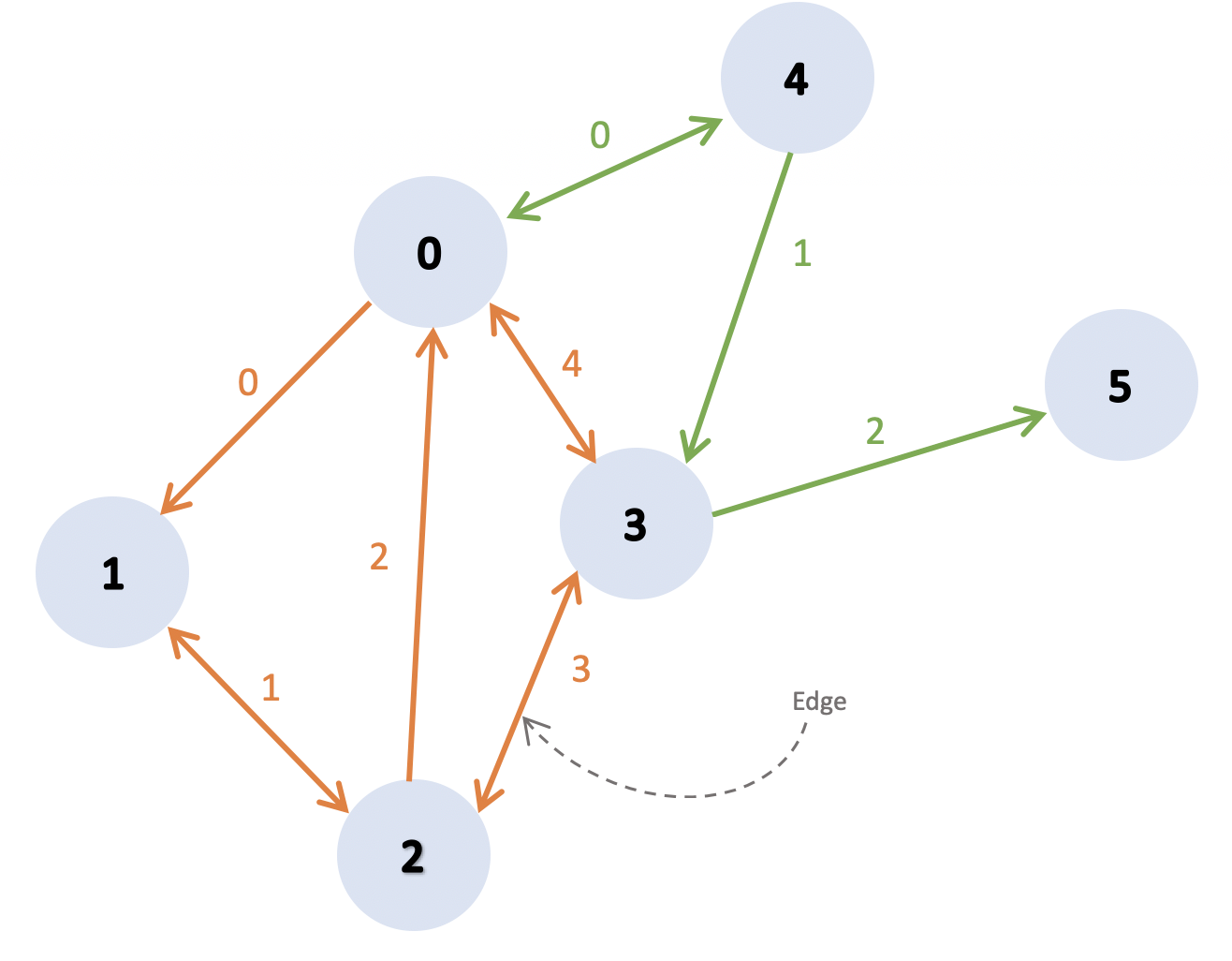
This image represents two graphs of MPI processes. The first graph contains the processes ranked 0, 1, 2, and 3. The second graph contains the processes ranked 0, 3, 4, 5. The mpi_grph structure is describing an MPI graph :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52 | TYPE mpi_grph
type(mpi_pool), pointer :: pool => mpi_world
integer(ip) :: ne ! Number of Edges (Two Sided Connected Ranks)
integer(ip) :: ne_send ! Number of Edges (One Sided Connected Ranks)
integer(ip) :: ne_recv ! Number of Edges (One Sided Connected Ranks)
type(mpi_com), allocatable :: edge(:) ! Edges Array
integer(ip) :: ireq
logical :: is_init = .false.
CONTAINS
procedure :: equal_mpi_graph
procedure, pass( self ) :: init => initialize_mpi_graph
procedure, pass( self ) :: wait_send => mpi_graph_wait_send
procedure, pass( self ) :: wait_recv => mpi_graph_wait_recv
procedure, pass( self ) :: wait => mpi_graph_wait
procedure, pass( self ) :: regen_typ => mpi_graph_regen_typ
procedure, pass( self ) :: mpi_graph_send_scal_i , &
mpi_graph_send_scal_r , &
mpi_graph_recv_scal_i , &
mpi_graph_recv_scal_r , &
mpi_graph_send_array_i , &
mpi_graph_send_array_r , &
mpi_graph_recv_array_i , &
mpi_graph_recv_array_r , &
mpi_graph_send_recv_scal_i , &
mpi_graph_send_recv_scal_r , &
mpi_graph_send_recv_array_i , &
mpi_graph_send_recv_array_r
generic :: assignment(=) => equal_mpi_graph
generic :: send => mpi_graph_send_scal_i , &
mpi_graph_send_scal_r , &
mpi_graph_send_array_i , &
mpi_graph_send_array_r
generic :: recv => mpi_graph_recv_scal_i , &
mpi_graph_recv_scal_r , &
mpi_graph_recv_array_i , &
mpi_graph_recv_array_r
generic :: send_recv => mpi_graph_send_recv_scal_i , &
mpi_graph_send_recv_scal_r , &
mpi_graph_send_recv_array_i , &
mpi_graph_send_recv_array_r
END TYPE mpi_grph
|
Example
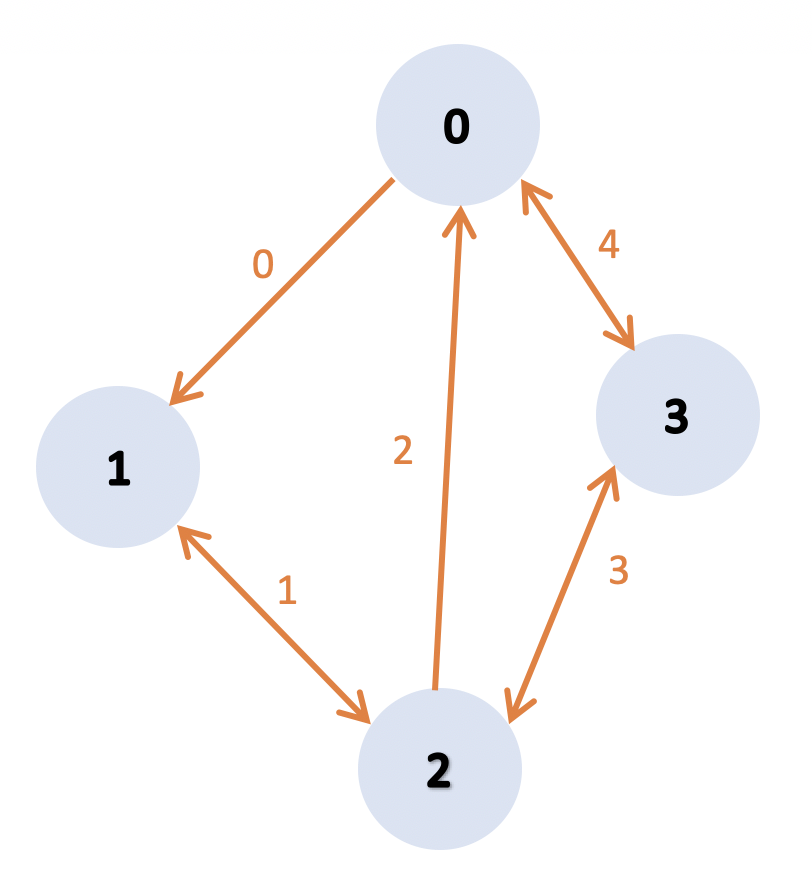 In this graph :
In this graph :
- the number of two sided connected processes is
ne = 3
- the number of one sided connected processes sending information is
ne_send = 2
- the number of one sided connected processes receiving information is
ne_recv = 2
| Process rank |
Receives from |
Sends to |
| 0 |
2 3 |
1 3 |
| 1 |
0 2 |
2 |
| 2 |
1 3 |
1 0 3 |
| 3 |
2 0 |
2 0 |
To use an MPI graph to enable communications between the processes, one should initialize the graph by calling the initialize_mpi_graph subroutine. One has to specify the number of two-sided connecting edges ne, and possibly a pool of processes to be targetted.
| MODULE SUBROUTINE initialize_mpi_graph( self , ne , pool )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(in ) :: ne
type(mpi_pool) , intent(in ), optional, target :: pool
END SUBROUTINE initialize_mpi_graph
|
MPI graphs only enable non-blocking communications. One can communicate by using the send, recv, send_recv routines, and wait for the end of sending, receiving or both communications by calling respectively the wait_send, wait_recv and wait routines.
Wait for the end of a non blocking communication
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | MODULE SUBROUTINE mpi_graph_wait_send( self )
class(mpi_grph), intent(in) :: self
END SUBROUTINE mpi_graph_wait_send
MODULE SUBROUTINE mpi_graph_wait_recv( self )
class(mpi_grph), intent(in) :: self
END SUBROUTINE mpi_graph_wait_recv
MODULE SUBROUTINE mpi_graph_wait( self )
class(mpi_grph), intent(in) :: self
END SUBROUTINE mpi_graph_wait
|
Non-blocking communications
The following subroutines define the communications of an integer, or an array of integers. The subroutines defining the communications of a real (or array of reals) are equivalent.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | MODULE SUBROUTINE mpi_graph_send_scal_i( self , to_send , withinfo )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(in ) :: to_send
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_graph_send_scal_i
MODULE SUBROUTINE mpi_graph_recv_scal_i( self , to_recv , withinfo )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(inout) :: to_recv
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_graph_recv_scal_i
MODULE SUBROUTINE mpi_graph_send_array_i( self , to_send , withinfo )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(in ) :: to_send(:)
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_graph_send_array_i
MODULE SUBROUTINE mpi_graph_recv_array_i( self , to_recv , withinfo )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(inout) :: to_recv(:)
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_graph_recv_array_i
|
Sending/Receiving Non-Blocking Communications
The following subroutines define the communications of an integer, or an array of integers. The subroutines defining the communications of a real (or array of reals) are equivalent.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | MODULE SUBROUTINE mpi_graph_send_recv_scal_i( self , to_send , to_recv , withinfo )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(inout) :: to_send
integer(ip) , intent(inout), optional :: to_recv
logical , intent(in ), optional :: withinfo
END SUBROUTINE mpi_graph_send_recv_scal_i
MODULE SUBROUTINE mpi_graph_send_recv_array_i( self , to_send , to_recv , withinfo , withtmp )
class(mpi_grph), intent(inout) :: self
integer(ip) , intent(inout) :: to_send(:)
integer(ip) , intent(inout), optional :: to_recv(:)
logical , intent(in ), optional :: withinfo
logical , intent(in ), optional :: withtmp
END SUBROUTINE mpi_graph_send_recv_array_i
|
Usage
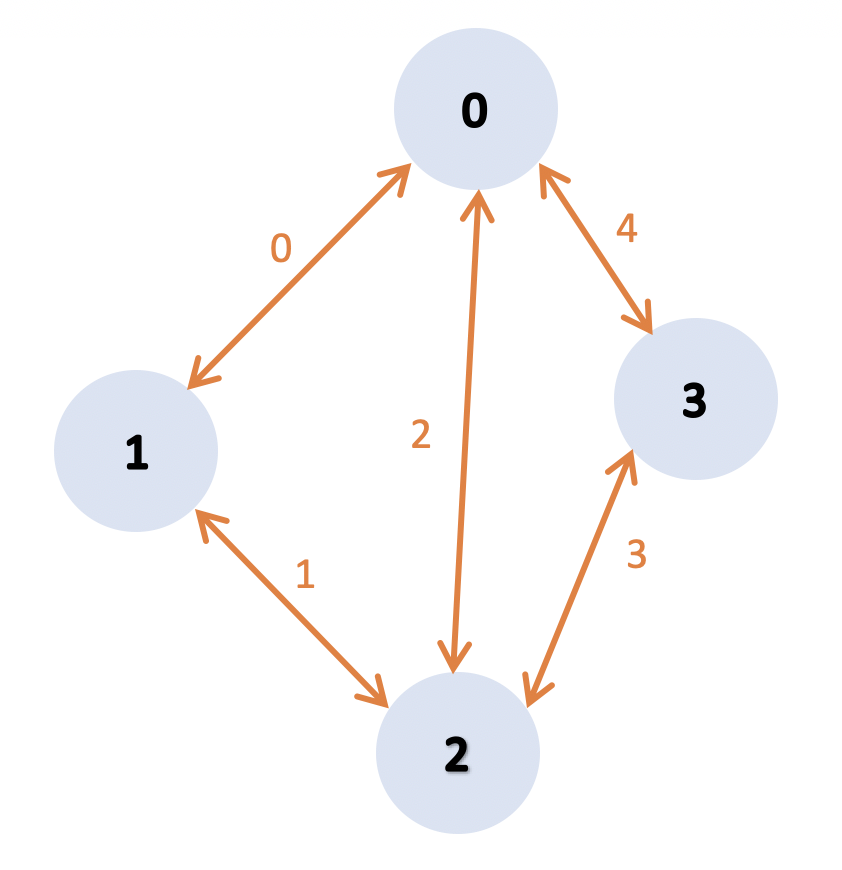 To initialize this MPI graph, one can write :
To initialize this MPI graph, one can write :
type(mpi_pool) :: mpi_world
type(mpi_grph) :: mpi_graph
[...]
call mpi_graph%init( ne = 5 , pool = mpi_world )
Then, one can define the communicating processes contained in this graph. The edge variable is an array of point-to-point communicators (mpi_com).
call mpi_graph%edge( 0 )%init( send_rank = 0 , recv_rank = 1 , twoside = T )
call mpi_graph%edge( 1 )%init( send_rank = 1 , recv_rank = 2 , twoside = T )
call mpi_graph%edge( 2 )%init( send_rank = 0 , recv_rank = 2 , twoside = T )
call mpi_graph%edge( 3 )%init( send_rank = 2 , recv_rank = 3 , twoside = T )
call mpi_graph%edge( 4 )%init( send_rank = 3 , recv_rank = 4 , twoside = T )
The following example shows the communication of global indexes of the mesh cells. Since the mesh is partitioned between each process, the mesh cells' indexes are obviously different between processes.
type(msh) :: mesh
[...]
call mpi_graph%send_recv( mesh%cell(:)%glob , withtmp = T )
[...]
This mpi_grph structure is fully used to handle communications between mesh partitions. See Mesh to further understand the use of this structure.
Question
Why withtmp optional ? Should be always present to avoid blocking ?